

Defining the Ideal Mobile ML Stack
Defining the Ideal Mobile ML Stack
Making Sense of a Challenging Landscape

Hi everyone! In today’s newsletter, we’ll be exploring what the mobile machine learning stack is, and what it should look like in the near-to-mid future as ML becomes more commonplace across different applications.
What Exactly is Machine Learning?
Or better yet, what is machine learning to media developers? Everywhere you look, you’ll often be greeted with either complicated mathematics, confusing images of graphs, or some combination thereof. But for us media developers, we don’t care for these gory details, and we shouldn’t have to care. To us, machine learning is simply a kind of function that we call with some data—whether an image, audio, text, or some combination thereof—and receive some form of structured information from. Just about every single application of ML, from style transfer to text generation, fits within this paradigm.

In order to build applications with ML, developers need an ML stack. The stack will cover everything from designing and training ML models to deploying them within our app. Let’s go through each step.
Designing ML Models
Don’t waste your time. The best way to explain this is with a little anecdote. For the past five years, I have worked on using computational photography and deep learning to enhance professional real estate photographs. Our company was called Homedeck, and almost all of our product was built on a pipeline of machine learning models we had designed and trained from scratch.


In hindsight, most of that design and training was a waste of time. This is because research labs scattered across the world—between companies like DeepMind and OpenAI, or universities like Berkeley and MIT—have a much stronger ability to design extremely effective ML models than most smaller companies or indie developers. This is reflected in the fact that the State of the Art (“SOTA”) in different ML tasks only tends to ever last for a few weeks, before some new research lab comes up with an even better method.
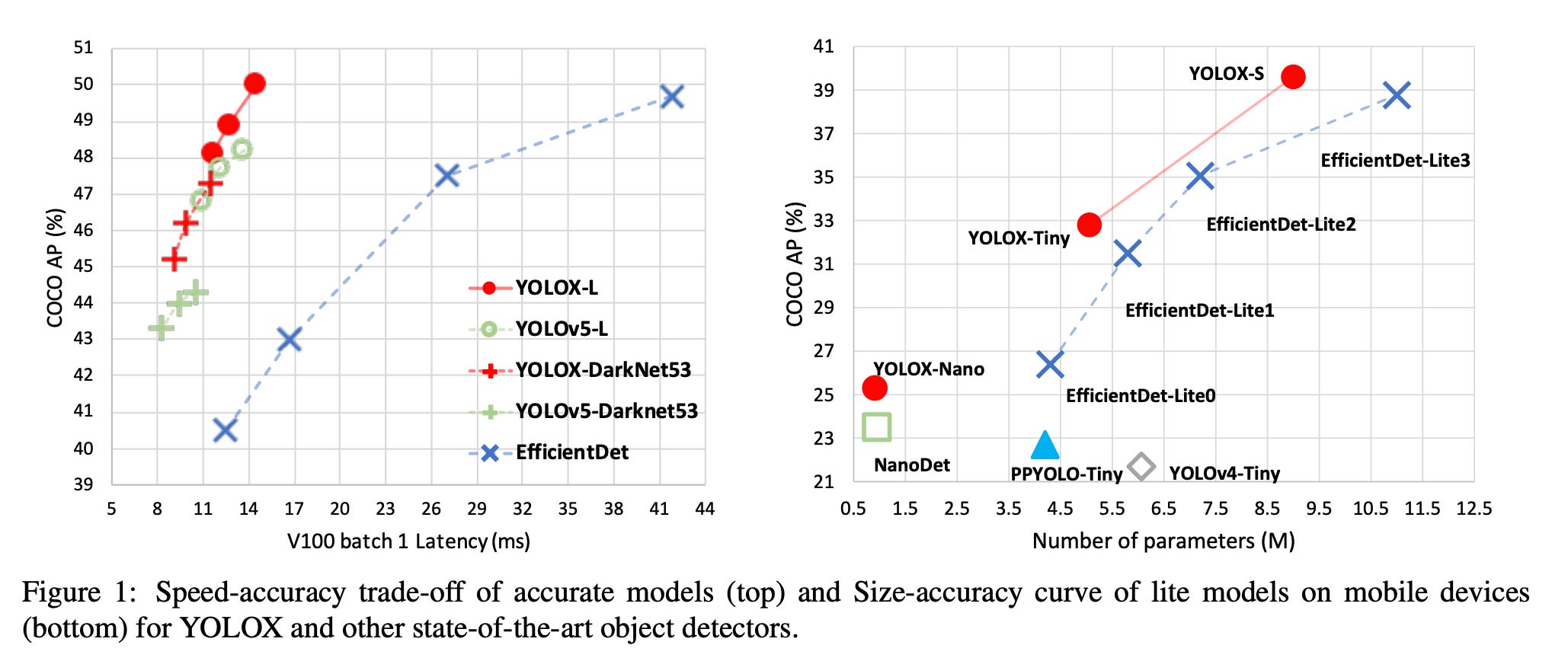
The key takeaway from all this is that you will almost never need to actually design an ML model—or technically speaking, a neural architecture—by yourself. Instead, you should aim to retrain an existing model on your own data.
Training ML Models
Some applications can use (pre-trained) ML models as-is without any further refinement on custom or proprietary data. Tasks like pose detection fall into this category, because almost nobody will need to refine a such a model on their own data. But for some other, more-general tasks like classification or detection, it is very common to want to refine these models to data that you have.
The process of refining a model to your custom data is called Transfer Learning. It is becoming an increasingly popular method for training models for the aforementioned reasons. The challenge with transfer learning is that because the ML landscape is highly fragmented, different ML projects have different configurations and requirements for how to train; one project might use TensorFlow and expect data annotations in one format, whereas another might use PyTorch with a different data annotation format. Currently, there aren’t many good solutions to this chaos.

We’ve been very quietly working on a project to aggregate all these disparate ML research projects into one easy-to-use, visual platform. It’s called Function, and provides developers with a low-code visual interface to plug their data in, then retrain a model. If you’re interested, join the waitlist.
Deploying ML Models
Once you have a trained model, whether directly from a research project or from fine-tuning an existing model with your data, you can deploy it to your application with NatML. NatML uses the Open Neural Network Exchange (ONNX) standard for exchanging and running ML models. With this foundation in place, NatML Hub aggregates all of these models into an easily-searchable catalog. You can upload your model to Hub, upload a predictor package, then publish the model.
Hub will soon introduce paid models, allowing developers to sell their own fine-tuned models. The goal is to create an abundant supply of models for different tasks, reducing the need for developers to ever have to fine-tune models by themselves.
Check out NatML Hub for new models, and join us on Discord to discuss the latest in machine learning and media tooling for interactive applications. And if you haven’t already, make sure to star the NatML open source API on GitHub. This will help us get the attention of more developers and grow the community!